
이분(이진)탐색
정렬된 데이터
: 데이터의 종류에 따라서
더욱 특화된 알고리즘을 사용하여 빠르게 처리할 수 있다
따라서 ‘정렬할 수 있는 데이터’의 경우,
그에 특화된 ‘이진탐색’이라는 알고리즘을 이용하여
더 효율적으로 데이터를 탐색할 수 있다
그렇다고, ‘데이터가 들어올 때 마다’
배열을 정렬하는 것은 ‘배보다 배꼽이 더 클 수 있다’는 점을 명심하자!
정렬 알고리즘이 이진 탐색 알고리즘보다 시간 복잡도가 높기 때문!!
이진탐색
‘이미 정렬된 데이터 배열’에서 ‘어떠한 값’의 위치를 찾을 때,
사용하는 알고리즘이다
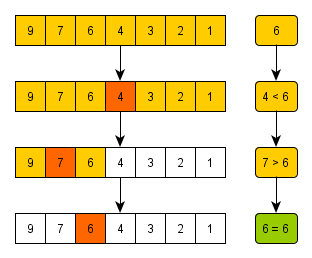
[출처] : https://woodforest.tistory.com/32
정렬되어 있는 데이터 구조에서 ‘탐색 범위’를
절반씩 좁혀나가며 데이터를 탐색한다
시간 복잡도 : O(log N) (log : log2)
‘분할 정복’ 알고리즘의 하나!
(모든 영역을 방문하지는 않음!)
‘재귀’로 쉽게 작성이 가능
- 예시코드 (Python)
# 오름차순으로 정렬되어 있다고 가정하며, 찾았을시 인덱스를 반환 def bsSearchRecur(nums : list, left : int, right : int, value : int)->int: # 찾기 실패!! if left > right: return -1 mid = (left + right) // 2 if list[mid] == value: # 찾았다! return mid elif list[mid] < value: # 중간값이 value보다 작네?? return bsSearchRecur(nums,mid + 1, right,value) # 중간값이 value 보다 크다! return bsSearchRecur(nums,left, mid - 1,value)
이진 탐색 과 선형 탐색
선형 탐색의 시간 복잡도는 O(N)이다
이진 탐색의 시간 복잡도는 O(log n)이지만,
정렬 알고리즘의 시간 복잡도를 고려해야 한다
ex : 병합 정렬을 사용한다고 한다면
정렬 후, 이진 탐색하면 시간 복잡도는
O(log n) + O(n log n) -> O(n log n)이 됨
- 그러면 이진 탐색 말고 그냥 선형 탐색 쓰는게 좋지 않나??
- 데이터가 들어오는 빈도는 적지만,
‘탐색’을 사용해야 할 일이 많은 경우
이진 탐색이 더욱 효율적!!
tmi) 정수론
꽤 방대한 양을 다루며,
좋은 포스팅 글을 찾았기에 잠시 링크를 남겨둔다
[생새우초밥집]https://freshrimpsushi.github.io/categories/%EC%A0%95%EC%88%98%EB%A1%A0/
댓글남기기