
연결 리스트
연결 리스트
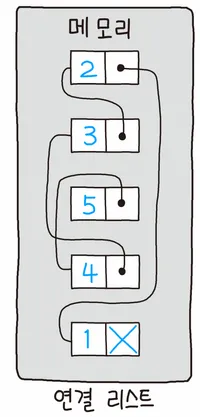
배열과 같은 ‘연속된’ 메모리 공간을 잡는 것이 아닌,
하나의 Node(데이터)가 다음 Node 를 가리키는(포인터)
방식으로 만들어진 자료구조
일반적으로는 다음 노드를 가리키는 포인터를 사용하지만,
추가적으로 ‘이전 노드’를 가리키는 포인터를 사용하는 ‘이중 연결 리스트’ 와
‘마지막’ 노드가 ‘처음’ 노드를 가리키는
‘순환 연결 리스트’ 방식도 존재한다
-
- 연결방식?
- 하나의 노드가 ‘다음’ 노드의 주소를 가리키는 방식을 이용
(다음 노드가 없다면 NULL을 가리킨다)
-
- 삽입 방식
- 연결 리스트는 가리키는 ‘포인터’를 다른 것으로 바꿈으로서 삽입을 할 수 있다!!
간단한 예시를 들어보자.
- a -> b의 연결리스트에서 c라는 노드를
a 와 b 사이에 삽입하고 싶다 - a가 b를 가리키는 포인터를 c로 가리키도록 수정
- c의 다음 포인터를 b로 수정
결과 : a -> c -> b
-
- 삭제 방식
- 자신 노드의 ‘이전’ 노드의 포인터가,
자신 노드의 ‘다음’ 노드를 가리키도록 수정
- a -> c ->b의 연결리스트에서 c라는 노드를
삭제하고 싶다 - a가 c를 가리키는 포인터를 b로 가리키도록 수정
- c의 데이터 할당을 해제하며 초기화
(메모리 관리를 프로그래머가 하는 경우,
놓치지 말 것!!)
-
- 검색 방식
- 첫 노드부터 찾을 때까지 뒤진다
(스택,큐 와 비슷한 방식)
연결 리스트의 시간 복잡도
- 삽입 : O(1) (이미 삽입할 위치를 아는 경우)
- 삭제 : O(1) (이미 삭제할 위치를 아는 경우)
- 검색 : O(N) (색인 접근이 불가능!)
연결 리스트의 특징
- 삽입, 삭제가 효율적(O(1))
-
검색이 느림(O(n))
=> 따라서 ‘요소 간 순서’가 중요하지 않으며,
데이터의 삽입, 삭제가 빈번한 경우 고려
(일반적인 경우는 ‘동적 배열’을 더 많이 사용)
(배열의 크기가 작은 경우,
캐시의 지역성으로 성능상 유리한 경우가 많기에) - 시스템, 커널 모드 프로그래밍 등에서는
배열보다 고려된다고 함
연결 리스트 구현 예시(Python)
- Node 클래스
from __future__ import annotations # 변수 주석을 간단하게 사용하기 위한 import
from typing import Any,Type
class Node:
"""노드용 클래스"""
def __init__(self,data : Any = None,next : Node = None):
self.data = data # 데이터
self.next = next # 뒤쪽 포인터
- LinkedList 클래스
class LinkedList:
"""연결 리스트 클래스"""
def __init__(self) -> None:
"""초기화"""
self.no = 0 # 노드의 개수
self.head = None# 머리 노드
self.current = None # 주목 노드 (노드 검색 등의 용도)
def __len__(self)->int: # 이러면 len(LinkedList Type)이 가능해지며 self.no를 return
return self.no
# 검색 (못 찾은 경우 -1 반환)
def search(self, data:Any) -> int:
count = 0
ptr = self.head
while ptr is not None:
if ptr.data == data:
self.current = ptr
return count
count += 1
ptr = ptr.next
return -1
# 연결 리스트에 해당 'data'가 포함되어 있는지 확인
# 이 함수를 구현하면 'in' 연산자 적용 가능
# ex) if 3 in my_LinkedList: -> 에서 search(3) 과 동일하게 된다
# 이터러블 의 'in'과는 다른 방식
def __contains__(self,data:Any)->bool:
return self.search(data) >= 0
def add_first(self,data:Any)->None:
ptr = self.head # 삽입전 머리 노드
# 새로운 노드를 만들고 기존 머리 노드를 next ptr 요소로 전달
# 그리고 head,current를 새로운 노드로 설정
self.head = self.current = Node(data,ptr)
self.no += 1
def add_last(self, data:Any):
if self.head is None:
self.add_first(data)
else:
ptr = self.head # 머리부터 검색
while ptr.next is not None: # 맨 끝까지...
ptr = ptr.next
ptr.next = Node(data,None) # 맨 끝 노드가 가리키는 곳에 새로운 노드 생성
self.no += 1
def remove_first(self)->None:
if self.head is not None: # 연결 리스트가 비어있지 않은 경우
self.head = self.current = self.head.next
self.no -=1
def remove_last(self)->None:
if self.head is not None:
if self.head.next is None: # 노드가 한개 뿐이네?
self.remove_first()
else:
ptr = self.next # 삭제할 노드를 가리킬 포인터
pre = self.head # 삭제 이전의 노드를 가리킬 포인터
while ptr.next is not None:
pre = ptr
ptr = ptr.next
pre.next = None
self.current = pre
self.no -= 1
def remove(self,p : Node)->None:
"""노드 p를 삭제"""
if self.head is not None:
if p is self.head:
self.remove_first()
else:
ptr = self.head
while ptr.next is not p: # p를 찾을때까지
ptr = ptr.next
if ptr is None: # p가 없는 상황이므로
return
ptr.next = p.next # 삭제하기 위하여 '다음' 노드의 위치를 받음
self.current = ptr
self.no -= 1
def remove_current_node(self)->None:
"""현재 주목 노드 삭제"""
self.remove(self.current)
def clear(self)->None:
"""전체 노드 삭제"""
while self.head is not None:
self.remove_first()
self.current = None
self.no = 0
def next(self)->bool:
"""주목 노드를 한칸 뒤의 노드로 이동"""
# 리스트가 비어있거나, 해당 주목 노드의 다음 노드가 없음
if self.current is None or self.current.next is None:
return False
self.current = self.current.next
return True
def print_current_node(self)->None:
"""주목 노드를 출력"""
if self.current is None :
print('주목 노드가 존재하지 않습니다')
else:
print(self.current.data)
# 모든 노드 출력
def print_all(self)->None:
ptr = self.head
while ptr is not None:
print(ptr.data)
ptr = ptr.next
def __iter__(self) -> LinkedListIterator:
"""이터레이터 반환"""
return LinkedListIterator(self.head)
- linkedListIterator 클래스
# 이터레이터용 함수가 있어야 # 해당 클래스를 '이터러블'이 가능하다고 여겨 # for a in b 등의 용법을 사용 가능하다 한다 class LinkedListIterator: """클래스 LinkedList의 이터레이터용 함수""" def __init__(self,head:Node): self.current = head def __iter__(self)->LinkedListIterator: return self def __next__(self)->Any: if self.current is None: raise StopIteration else: data = self.current.data self.current = self.current.next return data
댓글남기기